在与数据仓库、数据湖或数据库间数据传输的场景中,增量同步是一种高效且资源友好的方式,尤其在处理大规模数据时。当只需同步单张表的新增或变更数据时,Ckettle提供了灵活的配置选项来实现这一目标。
一、什么是单表增量同步?
单表增量同步指的是仅同步目标表中发生变化的数据(如新增、更新或删除记录),而不是每次都全量覆盖。这种方法能够显著减少数据传输量、降低系统负载并提高同步效率。
二、Ckettle简介
Ckettle是一款开源的ETL(Extract, Transform, Load)工具,基于Java开发,支持多种数据源和目标,包括关系型数据库(如MySQL、Oracle)、文件系统(如CSV、Excel)和大数据平台(如Hadoop、Hive)。其图形化界面使得配置数据流程变得简单直观。
三、实现单表增量同步的关键步骤
在使用Ckettle进行单表增量同步时,通常可以按照以下步骤操作:
- 识别增量数据:
- 利用时间戳字段:如果表中包含最后修改时间(如
update<em>time或create</em>time),可以基于该字段筛选出上次同步后的新记录。
- 使用自增ID:若表中存在自增主键,可通过记录上次同步的最大ID值,仅同步ID大于该值的记录。
- 启用数据库日志(如MySQL的binlog):通过解析日志捕获变更,适用于高实时性场景。
- 配置Ckettle作业:
- 输入步骤:选择适当的数据输入组件(如“表输入”),并编写SQL查询以提取增量数据。例如:
SELECT * FROM your<em>table WHERE update</em>time > '上次同步时间'。
- 转换步骤:根据需要清洗或转换数据,例如过滤无效值、格式化字段。
- 输出步骤:使用“插入/更新”或“表输出”组件将数据写入目标表,并配置去重或更新逻辑。
- 调度与自动化:
- 利用Ckettle的作业调度功能(如结合cron或内置定时器),定期执行同步任务,确保数据及时更新。
- 记录同步状态(如最后同步时间或ID),以便下次任务从中断点继续。
四、实践示例:基于时间戳的同步
假设我们需将MySQL中的orders表增量同步到数据仓库,步骤如下:
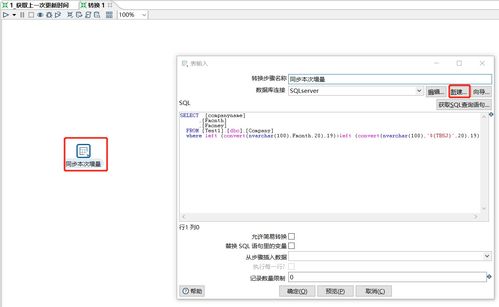
- 在
orders表中,last_modified字段记录每条订单的最后更新时间。 - 在Ckettle中创建转换:
- 使用“表输入”组件,SQL查询为:
SELECT * FROM orders WHERE last_modified > ?,并通过参数传入上次同步时间。
- 添加“插入/更新”组件,配置目标表结构,并设置
order_id为关键字段,实现更新或插入。
- 创建作业,添加该转换,并设置每天凌晨1点自动运行。
五、注意事项
- 数据一致性:在高并发环境中,需确保同步过程中源表数据不被修改,或采用事务隔离机制。
- 错误处理:配置日志记录和异常通知,便于及时排查同步失败问题。
- 性能优化:对大数据量表,可在源表上为时间戳或ID字段添加索引,提升查询效率。
六、总结
Ckettle为单表增量同步提供了强大而灵活的支持,通过合理配置,可以高效、可靠地实现数据流动。在实际应用中,结合具体业务需求选择增量策略,并注重监控与优化,将大大提升数据管理的整体效能。